The data for this project has been collected from psychcentral.com. This website offers an online forum for posting questions and answers related to mental health. Please visit https://forums.psychcentral.com for more information.
Check my final PDF for full code and visualization.
My aim is to identify the most important reasons for mental disorders. Whenever I think of mental disorder one questions pops up in my mind and that is - Is this something from their birth or people tend to suffer from this because of certain reasons or situations they have seen or faced in their lifetime? Only to find my answers, I get the dataset from the site mentioned above and lets see if we can find out anything interesting!
Here, I will be performing text analytics including creating word clouds, sentiment analysis and topic modeling.
I am using RStudios as my IDE and I load my dataset and find the number of columns that is in my data. It comes out there are only 4 columns:
- rows
- q_subject
- q_content
- answers
Here the first column is rows which is basically index starting from 1, 2 and so on. Second column is q_subject containing headline that the individual (with the mental stress) has written which is short but descriptive. Third column contains more brief information and details regarding the second column and last column is the reply on the individual.

The dataset has total of 8360 rows containing description of the patients.
Before using our data for analysis, we need to preprocess it. The main goal of pre-processing the text documents is to prepare the text for Text Mining methods. Depending on the type of TM method that we want to deploy, there are different pre-processing steps that we should take to prepare our text data. The main steps include:
-
Tokenization: Tokenization is the process of breaking a stream of text up into words, phrases, symbols, or other meaningful elements called tokens.
-
Convert to lower case: After tokenization, we usually need to convert all of the tokens into lower (or upper) case. This way, the software would not assume any difference between “Family” and “family”.
-
Stop-removal method: Another important pre-processing step is to remove stop-words from the text. Each language has its own list of stop-words. A comprehensive list of stop-words for many languages can be found here: http://www.ranks.nl/stopwords. Examples of stop-words include “a”, “an”, and “did”. Stop-words are basically a set of commonly used words in any language, not just English.
-
Stemming and Lemmitization: There are certain words in text like car, car's, cars' which is same but is taken into consderation seperately. Stemming and Lemmitization helps us to group them under one word only.
-
After tokeization and removing stop words, we found out our top tokens in the dataset.
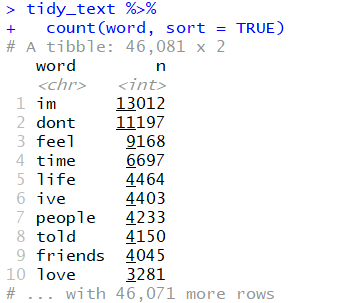
-
Let's use library “ggplot2” to create a visualization that shows the frequency of the tokens that appeared for at least 2000 times.
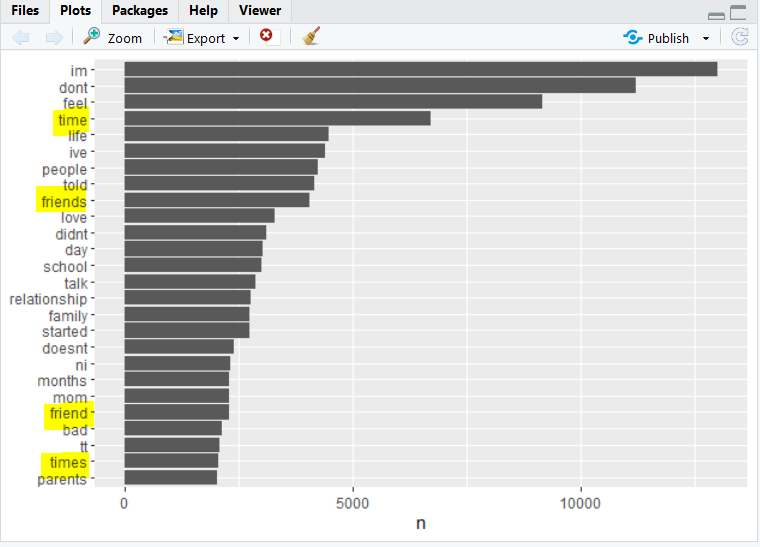
-
Now, you can see that I have highlighted certains words in the above image. If you see clearly we have repeating words with either s or es added ( friend and friends ) and therefore we need stemming on this text. For that, I have used SnowballC package in R to stem q_content first.


After stemming, we again applied tokenization and what we observed is that top tokens after stemming the text changes. Now they are:

- I use library “wordcloud” to create a word cloud with the 200 most used tokens to see if there is any word that stands out in their discription.

Things were not clear by just looking at these words. So i thought to segregate them on the basis of sentiment with color-coded words - Red for negative and blue for positive. For getting the sentiments, I use get_sentiments("bing") which has predefined sets of words for positive and negative meaning and after generating my word cloud again, I saw complete disntiguished pattern.

Words like scared, hate, depressed, wrong and bad are very common among people who suffer mental disability and also words like comfort, respect, love, trust and support are very much clear in this wordcloud.
- I repeat same for the answer column and found out most used words by the patients.

Here, words like love, trust, support, strong, hurt, wrong, pain and afraid are clear.
In text mining, we often have collections of documents, such as blog posts or news articles, that we’d like to divide into natural groups so that we can understand them separately. Topic modeling is a method for unsupervised classification of such documents, similar to “clustering” on numerical data, which finds natural groups of items even when we’re not sure what we’re looking for.
We are using LDA to determine the words. LDA is a mathematical method for estimating both of these at the same time: finding the mixture of words that are associated with each topic, while also determining the mixture of topics that describes each document.
Using this, we can group words into different category and see what is responsible for pateints mental behaviour, is it family, friends or work pressure?
After few LDA tuning, I found some groups of words like:

In my observation, as we increase k, the number of terms that are unique increases. For example in k=3 we have relationship and people which is not there in k=2. K=4 has sex, school and year which is not in k=3. So the recommended number of topics appropriate for this corpus would be k = 10 or more if you have large dataset.
I observe that there are certain words representing relation like relationship, parents, child, father and mother. Some are the terms that tells us about their place like school and forum. Some tell their emotions like love, depress, need, life.
So from these words, I can say that they are mainly affected by their relationships and may be they need a good one in their life ( we have words like good, relationshiop, need, life ). The society and the place where they live and go may have contributed in their feelings.
Overall, they might not be happy with the place they live or go and the relationship they share with either their family or friends . They may lack love and care which might be one of the reason for mental disorders in the society.
I am uploading the code. All you have to do is to download it and open it in RStudio or similar IDE.
Also, I have uploaded the pdf version of my code for a more visualization perspective.